Our demo videos showcase MaskHand's ability to reconstruct highly accurate and realistic 3D hand meshes from single RGB images, overcoming challenges like complex articulations, self-occlusions, and depth ambiguities.
MaskHand Training
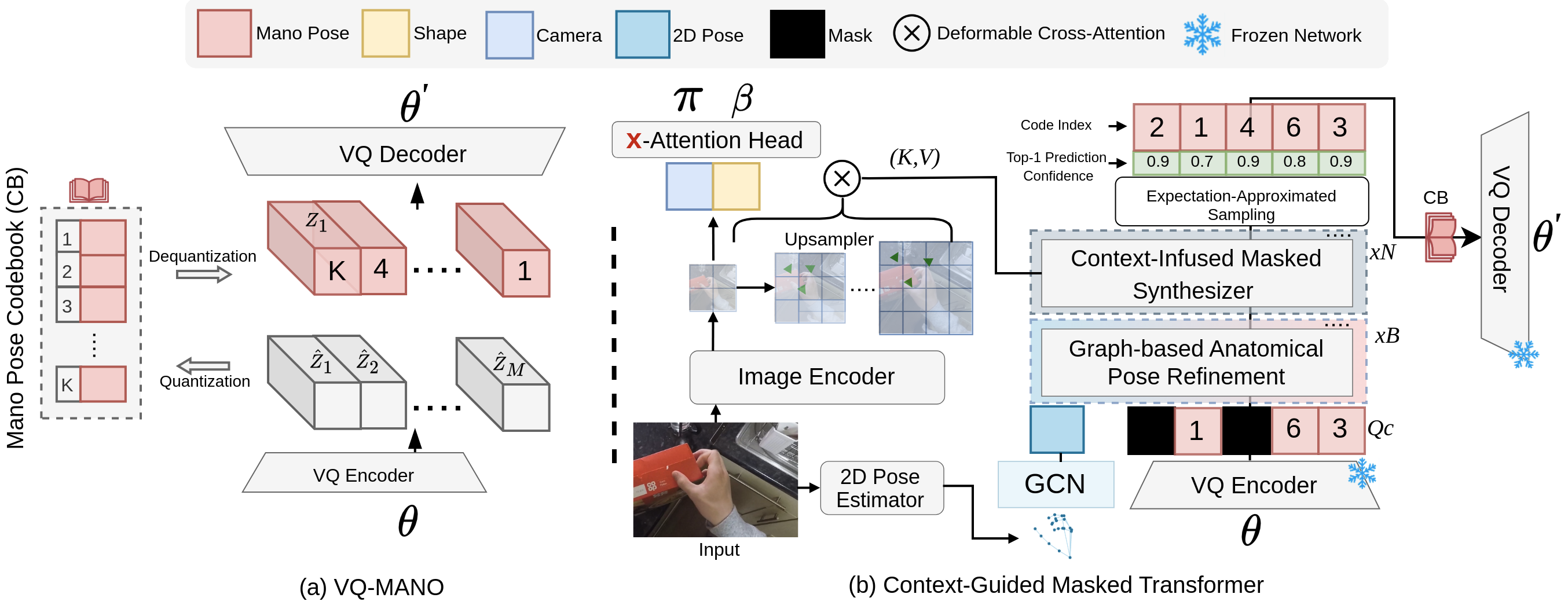
MaskHand Training Phase . MaskHand consists of two key components: (1) VQ-MANO, which encodes 3D hand poses into a sequence of discrete tokens within a latent space, and (2) a Context-Guided Masked Transformer that models the probabilistic distributions of these tokens, conditioned on the input image, 2D pose cues, and a partially masked token sequence.
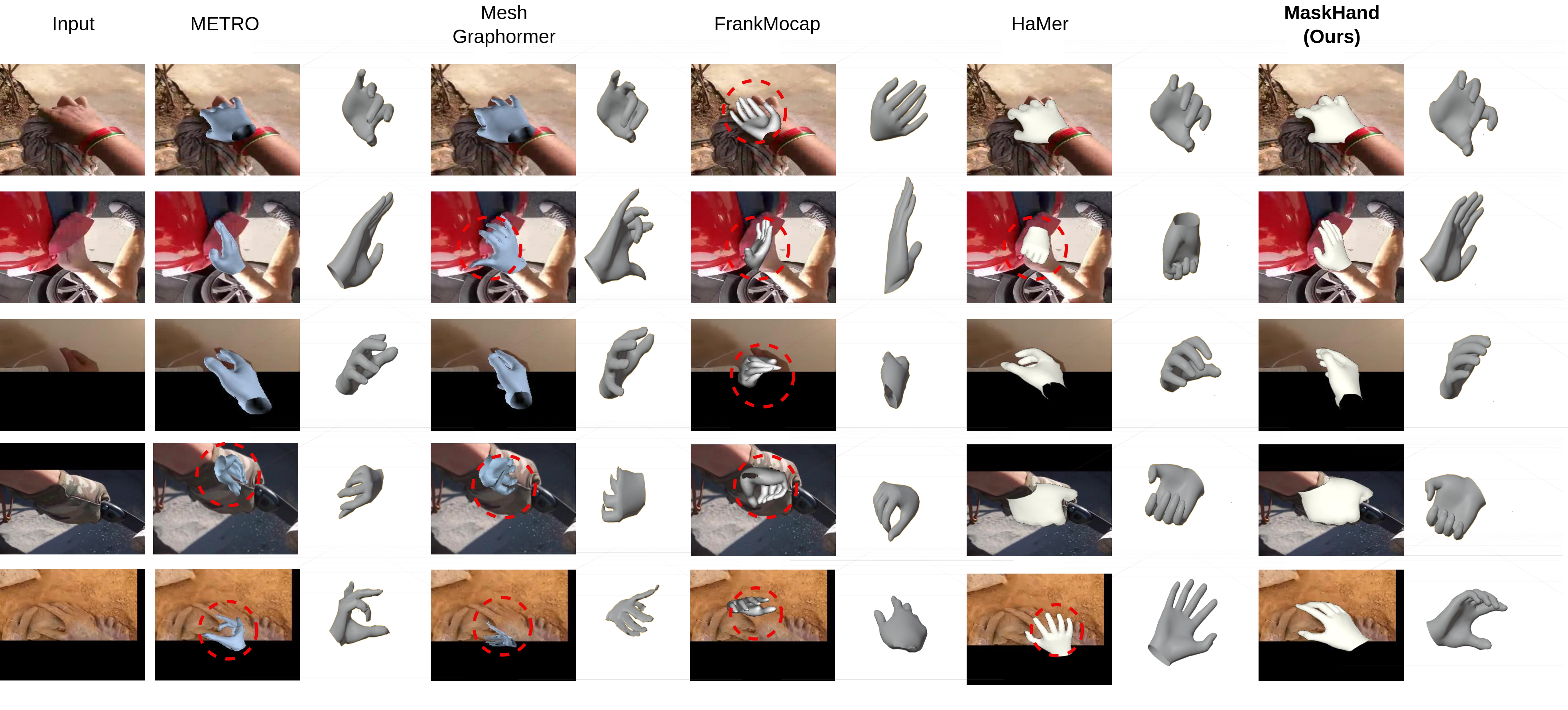
State-of-the-Art Comparison

Occluded Masked Regions around 80-90%: Challenging Poses


Multiple Reconstruction Hypotheses with Explicit Confidence Levels
Multiple reconstruction hypotheses with explicit confidence levels. The figure illustrates MaskHand's 3D hand mesh reconstructions in occluded scenarios, ranked by confidence. High-confidence hypotheses closely align with the ground truth, ensuring structural accuracy and fidelity. As confidence decreases (e.g., from the 100th to the 1000th hypothesis), reconstructions degrade, exhibiting distortions and unrealistic poses. This highlights the importance of prioritizing high-confidence hypotheses for robust and accurate 3D hand reconstruction.




HINT Benchmark: Challenging Poses in Wild
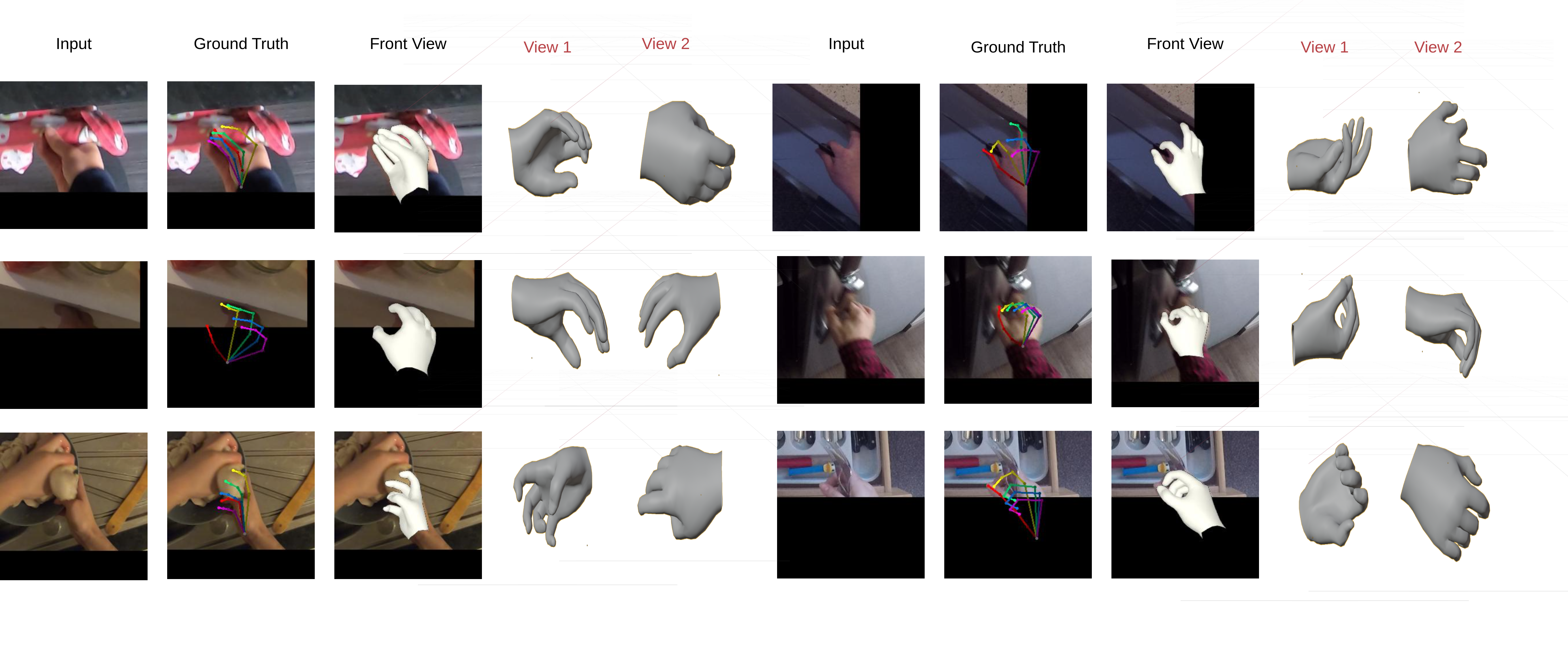
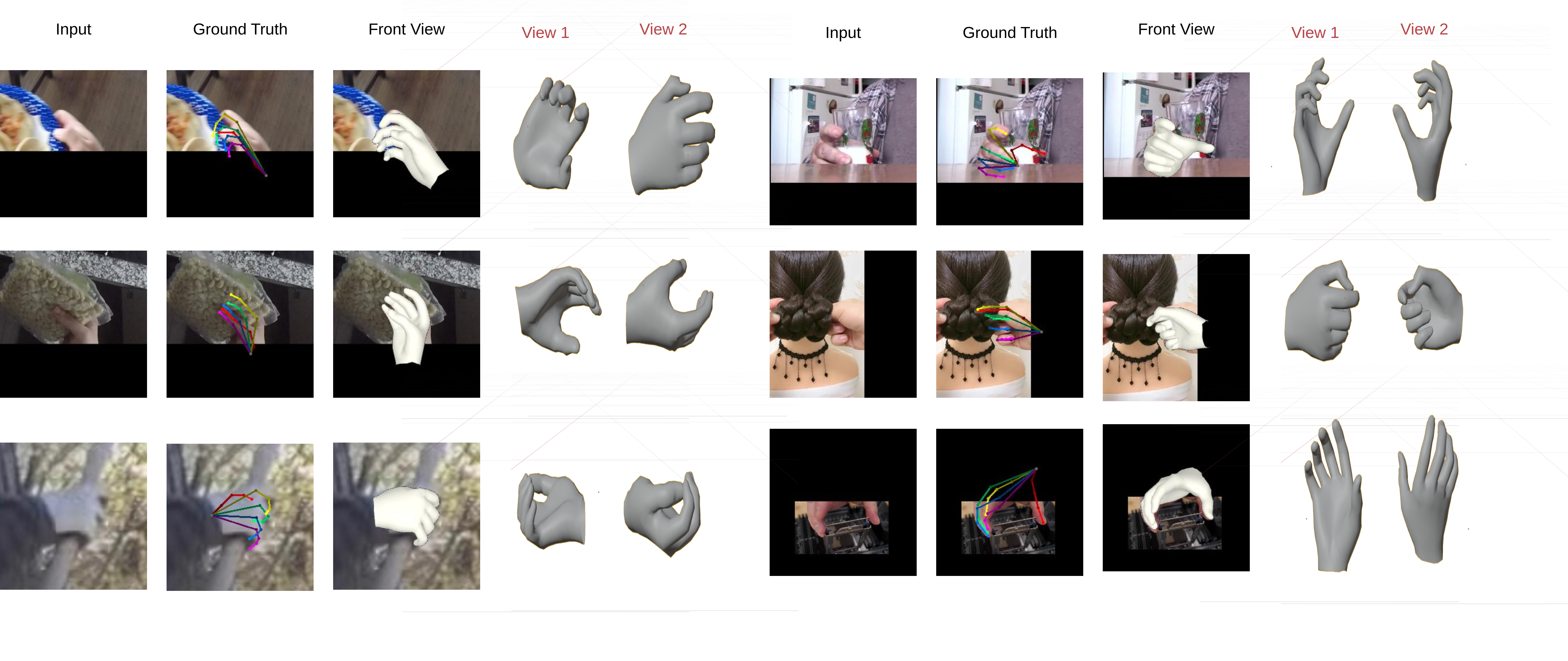
Visualizing In-Wild Results


Visualizing Reference Keypoints and their Offsets




Effectiveness of Proposed MaskHand Components



Text-to-Mesh Generation

Confidence-Aware Unconditional Mesh Generation
