LiveGesture
Streamable Co-Speech Gesture Generation Model
Muhammad Usama Saleem , Mayur Jagdishbhai Patel, Ekkasit Pinyoanuntapong, Zhongxing Qin, Li Yang, Hongfei Xue, Ahmed Helmy, Chen Chen, Pu Wang
University of North Carolina at Charlotte · University of Central Florida
For any inquiries, please email to: msaleem2@charlotte.edu
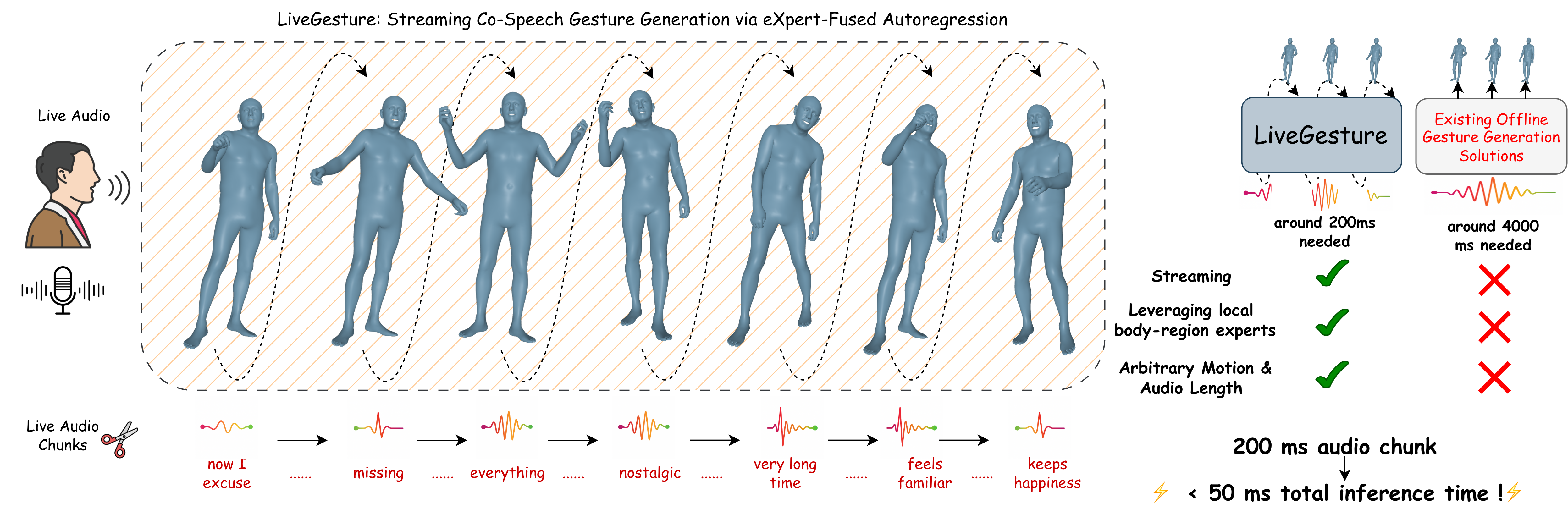
We propose LiveGesture, the first fully streamable, speech-driven full-body gesture generation framework that operates with zero look-ahead and supports arbitrary sequence length. Unlike existing co-speech gesture methods—which are designed for offline generation and either treat body regions independently or entangle all joints within a single model—LiveGesture is built from the ground up for causal, region-coordinated motion generation.
LiveGesture consists of two main modules: the Streamable Vector-Quantized Motion Tokenizer (SVQ) and the Hierarchical Autoregressive Transformer (HAR). The SVQ tokenizer converts the motion sequence of each body region into causal, discrete motion tokens, enabling real-time, streamable token decoding. On top of SVQ, HAR employs region-eXpert autoregressive (xAR) transformers to model expressive, fine-grained motion dynamics for each body region. A causal spatio-temporal fusion module (xAR-Fusion) then captures and integrates correlated motion dynamics across regions.
Both xAR and xAR-Fusion are conditioned on live, continuously arriving audio signals encoded by a streamable causal audio encoder. To enhance robustness under streaming noise and prediction errors, we introduce autoregressive masking training, which leverages uncertainty-guided token masking and random region masking to expose the model to imperfect, partially erroneous histories during training. Experiments on the BEAT2 dataset demonstrate that LiveGesture produces coherent, diverse, and beat-synchronous full-body gestures in real time, matching or surpassing state-of-the-art offline methods under true zero–look-ahead conditions.
Method Figures
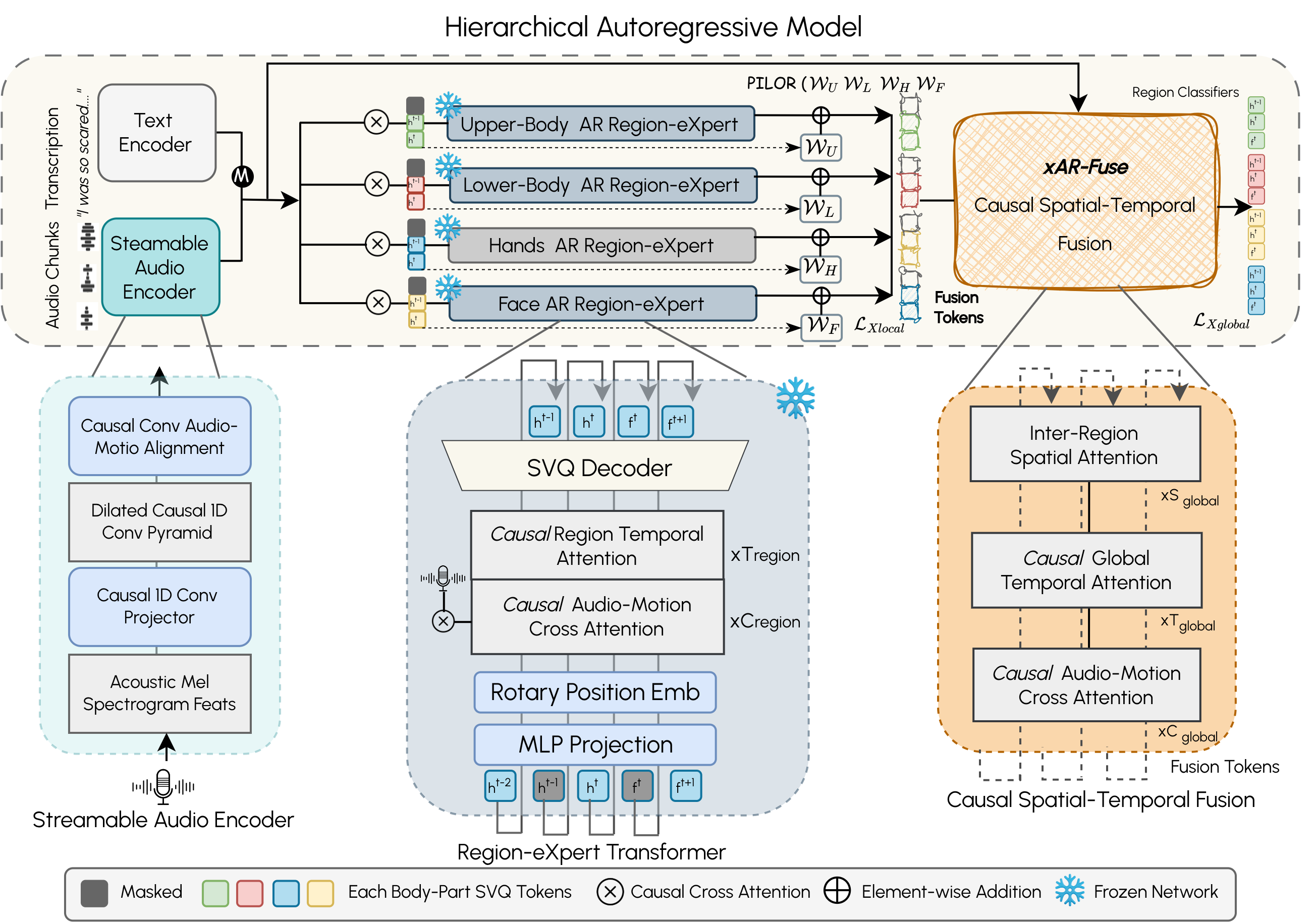
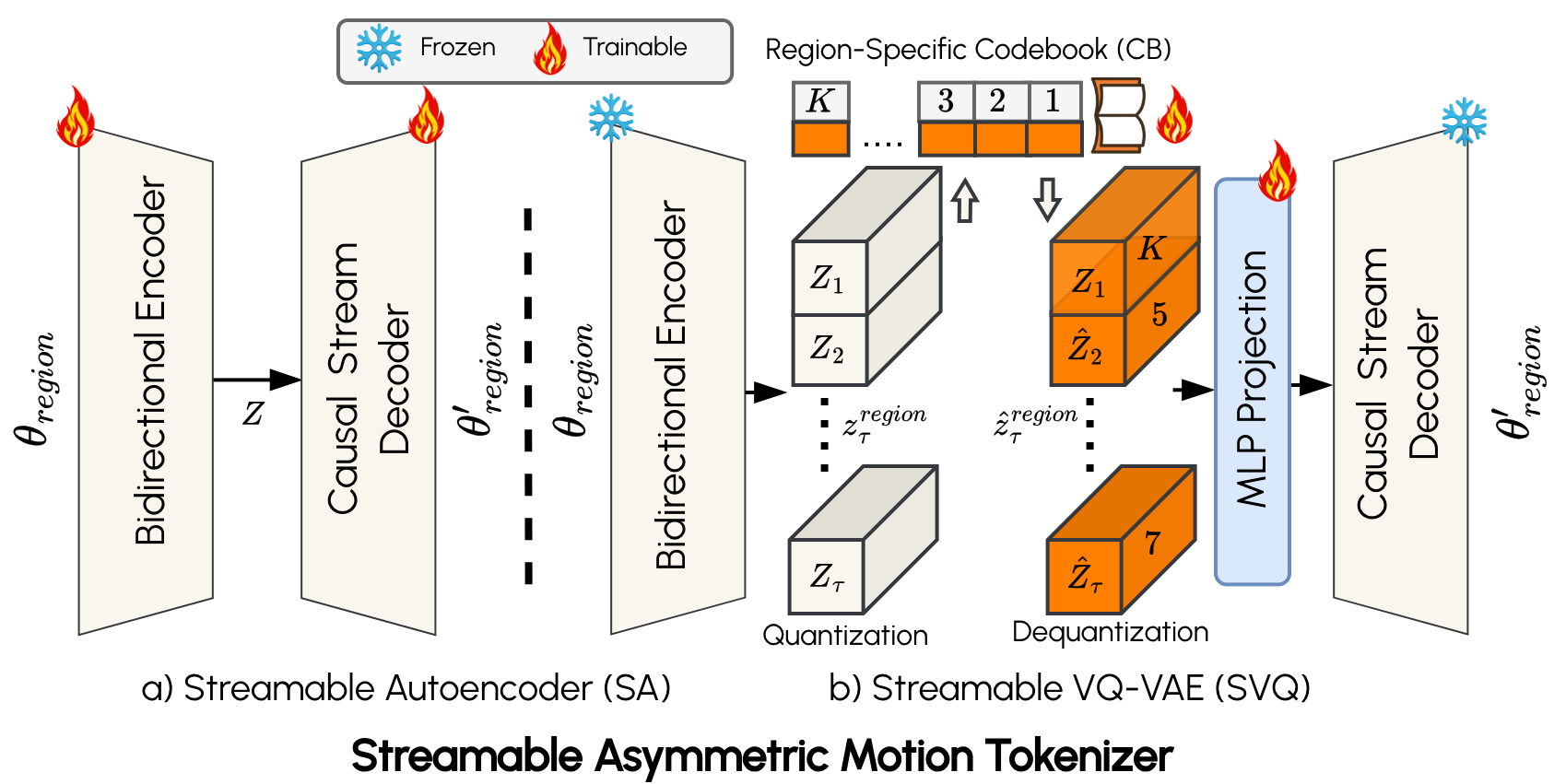
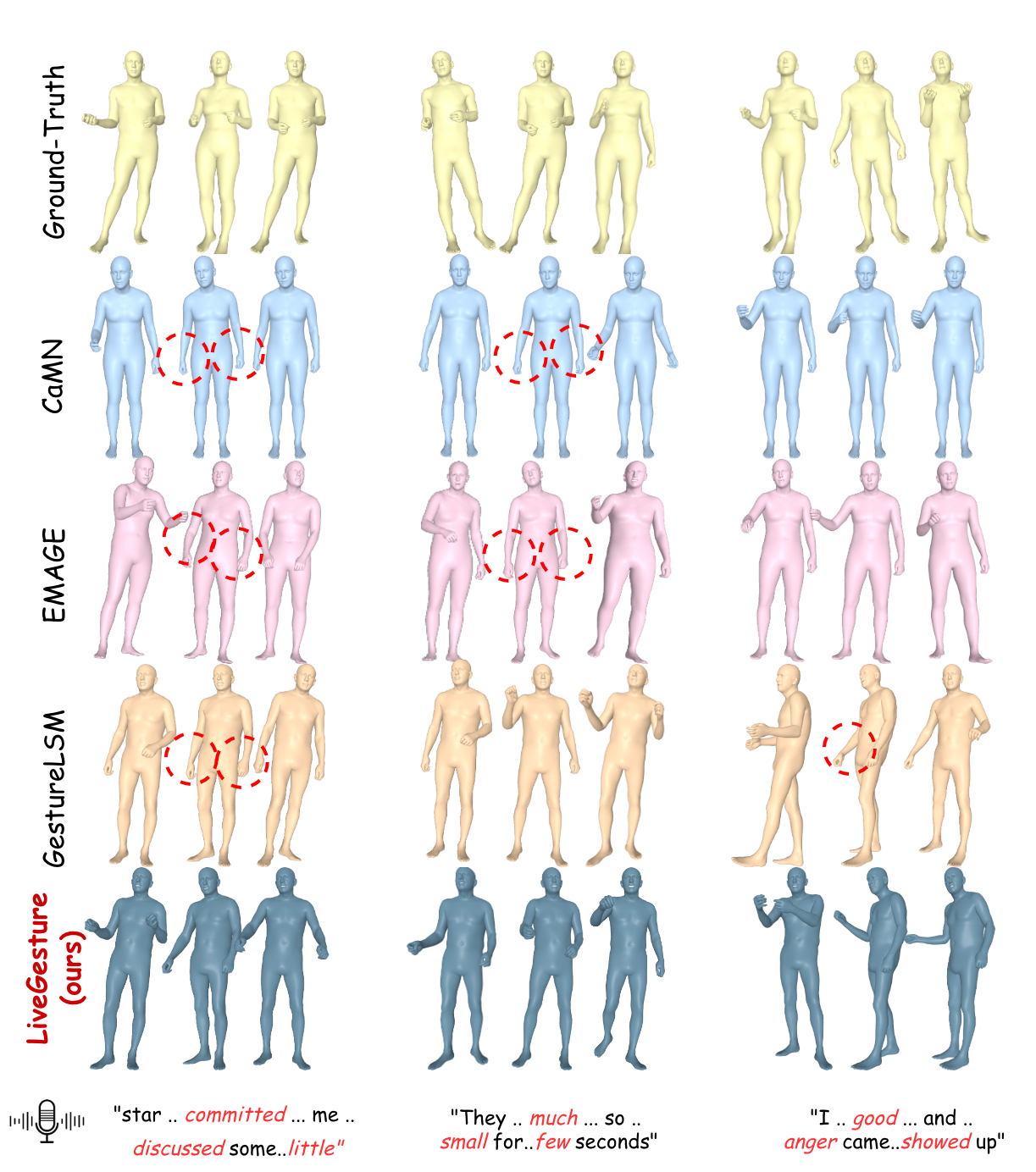
Results on BEAT2
| Method | Venue | Streaming | FGD ↓ | BC → | Div ↑ | MSE ↓ |
|---|---|---|---|---|---|---|
| HA2G | CVPR'22 | ✗ | 12.32 | 0.677 | 8.63 | -- |
| DisCo | MM'22 | ✗ | 9.42 | 0.643 | 9.91 | -- |
| CaMN | ECCV'22 | ✗ | 6.64 | 0.676 | 10.86 | -- |
| TalkShow | CVPR'23 | ✗ | 6.21 | 0.695 | 13.47 | 7.791 |
| DiffSHEG | CVPR'24 | ✗ | 7.14 | 0.743 | 8.21 | 9.571 |
| ProbTalk | CVPR'24 | ✗ | 5.04 | 0.771 | 13.27 | 8.614 |
| EMAGE | CVPR'24 | ✗ | 5.51 | 0.772 | 13.06 | 7.680 |
| MambaTalk | NeurIPS'24 | ✗ | 5.37 | 0.781 | 13.05 | 7.680 |
| SynTalker | MM'24 | ✗ | 4.69 | 0.736 | 12.43 | -- |
| RAG-Gesture | CVPR'25 | ✗ | 9.11 | 0.727 | 12.62 | -- |
| RAG-Gesture (w/ Disc.) | CVPR'25 | ✗ | 8.79 | 0.739 | 12.62 | -- |
| GestureLSM | ICCV'25 | ✗ | 4.25 | 0.729 | 13.76 | 1.021 |
| LiveGesture (ours) | – | ✓ | 4.57 | 0.794 | 13.91 | 1.241 |
BibTeX
@article{saleem2024livegesture,
title = {LiveGesture: Streamable Co-Speech Gesture Generation Model},
author = {Saleem, Muhammad Usama and Patel, Mayur Jagdishbhai and
Pinyoanuntapong, Ekkasit and Qin, Zhongxing and Yang, Li and
Xue, Hongfei and Helmy, Ahmed and Chen, Chen and Wang, Pu},
journal = {arXiv preprint -},
year = {2024}
}