Pruning Attention Heads of Transformer Models Using A* Search
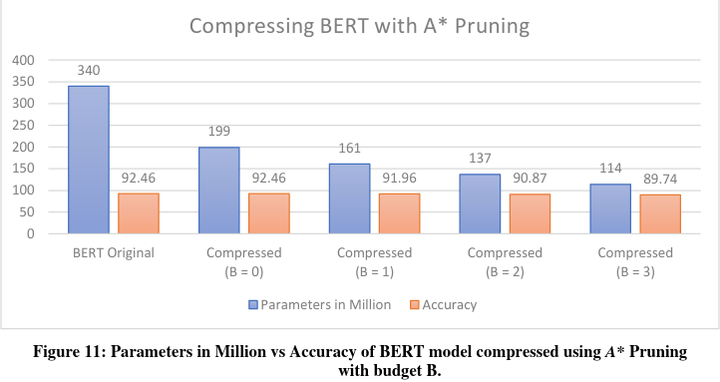 Results
Results
Abstract
Recent years have seen a growing adoption of Transformer models such as BERT in Natural Language Processing and even in Computer Vision. However, due to their size, there has been limited adoption of such models within resource-constrained computing environments. This paper proposes novel pruning algorithm to compress transformer models by eliminating redundant Attention Heads. We apply the A* search algorithm to obtain a pruned model with strict accuracy guarantees. Our results indicate that the method could eliminate as much as 40% of the attention heads in the BERT transformer model with no loss in accuracy.
Type
Publication
Arxiv